Abstract
LLMs and VLMs are increasingly deployed as embodied agents, yet existing benchmarks largely revolve around simple short-term tasks and struggle to capture rich realistic constraints that shape real-world decision making. To close this gap, we propose DeliveryBench, a city-scale embodied benchmark grounded in the real-world profession of food delivery. Food couriers naturally operate under long-horizon objectives (maximizing net profit over hours) while managing diverse constraints, e.g., delivery deadlines, transportation expenses, vehicle battery levels, and necessary interactions with other couriers and customers. DeliveryBench instantiates this setting in procedurally generated 3D cities with diverse road networks, buildings, functional locations, transportation modes, and realistic resource dynamics, enabling systematic evaluation of constraint-aware, long-horizon planning.
We benchmark a range of VLM-based agents across nine cities and compare them with human players. Our results reveal a substantial performance gap to humans, and find that these agents are short-sighted and frequently break basic commonsense constraints. Additionally, we observe distinct personalities across models (e.g., adventurous GPT-5 vs. conservative Claude), highlighting both the brittleness and the diversity of current VLM-based embodied agents in realistic, constraint-dense environments.
Benchmark Overview
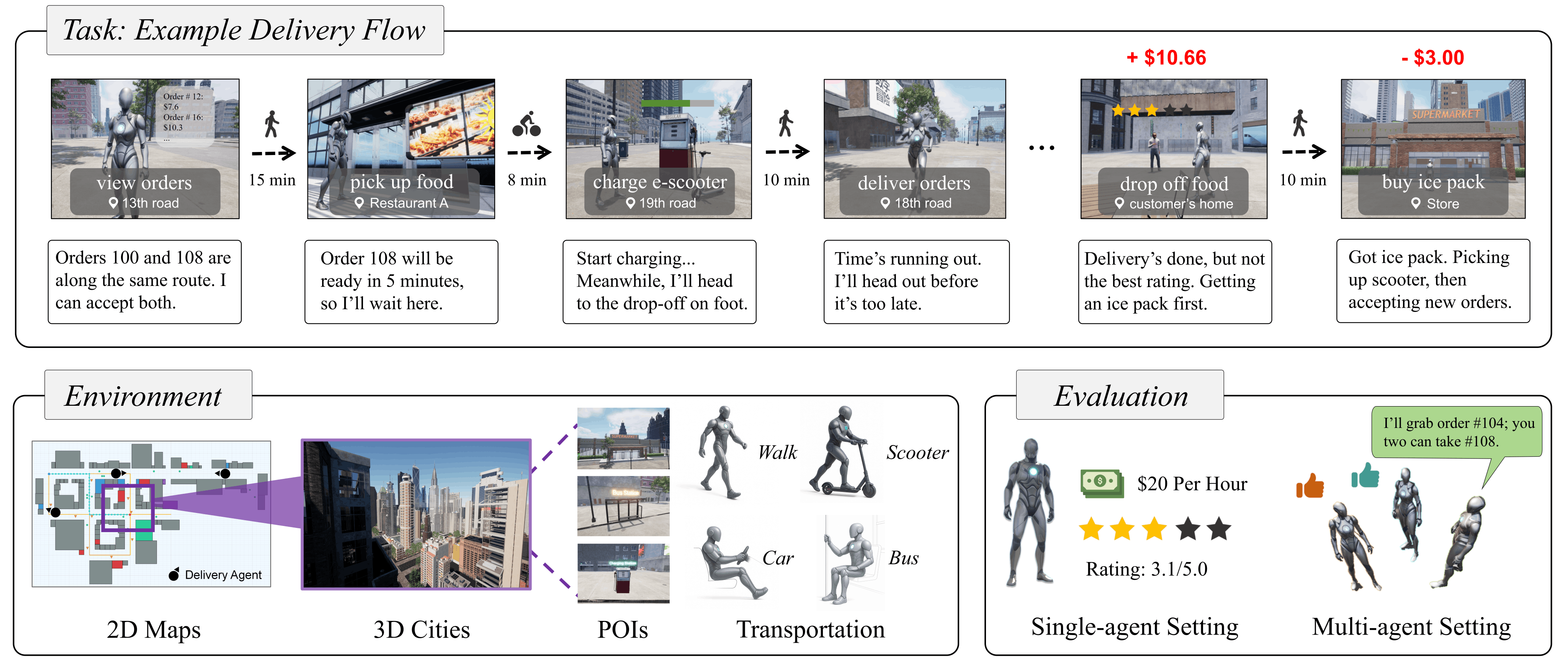
We center our benchmark on the food-delivery scenario, where an agent operates in a virtual city and aims to maximize net profit by continuously completing delivery orders. The delivery task is formalized as a long-horizon constrained optimization problem, in which a VLM-based agent, acting as a courier, seeks to maximize net profit over an operational horizon (e.g., two virtual hours). To achieve this goal, the agent must plan and execute a sequence of delivery and supportive tasks while respecting a diverse set of real-world constraints. When multiple agents coexist, they additionally encounter social dynamics such as competition and collaboration.
Key Features
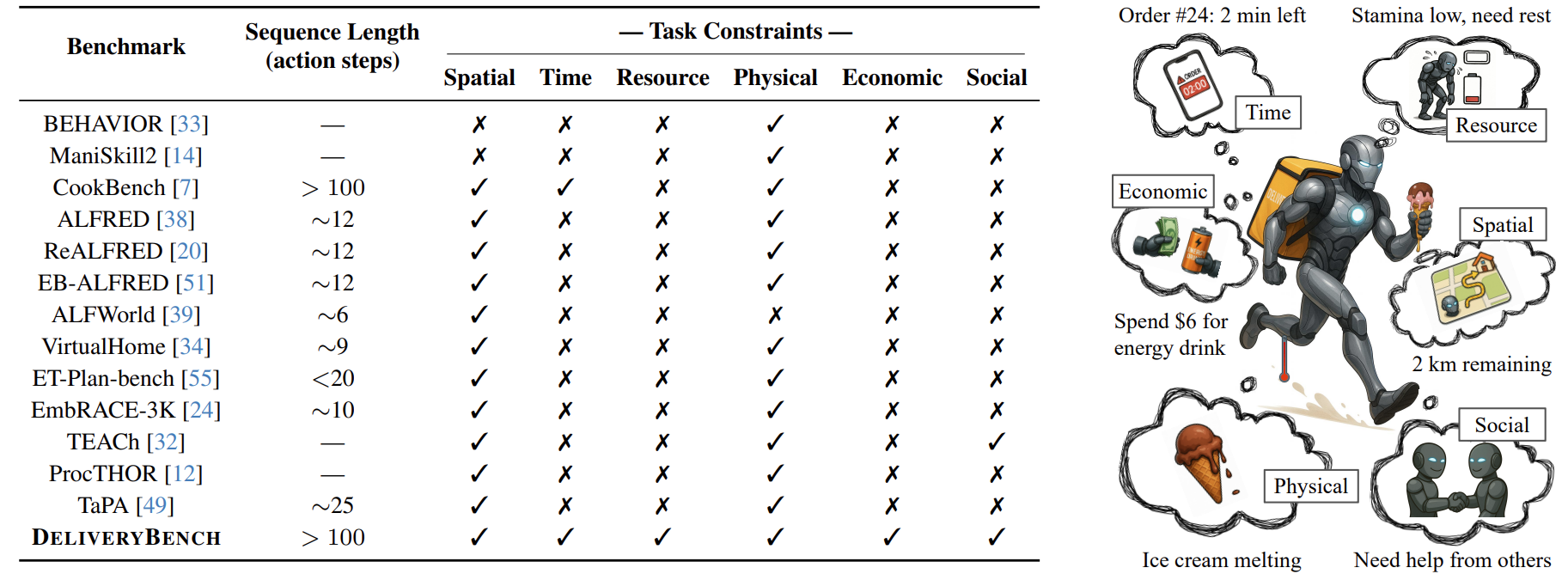
Compared with prior embodied benchmarks, DeliveryBench supports
long-horizon tasks (several in-game hours; typically > 100 action steps)
with multi-dimensional real-world constraints, including:
Time constraints. Tasks feature deadlines and time windows that determine
when they can be performed. Agents must schedule actions to avoid late deliveries
and make efficient use of limited working time.
Spatial constraints. Many actions are only valid at specific locations,
so agents must navigate 3D cities and visit appropriate POIs in the correct order
(e.g., restaurants, charging stations).
Resource constraints. Agents must manage consumables such as stamina,
vehicle battery, and cash to stay operational, sometimes transforming one resource
into another (e.g., buying an energy drink to restore stamina).
Physical constraints. Environmental dynamics (e.g., temperature, motion,
collisions) affect food quality, requiring agents to consider item fragility and
perishability in route planning.
Economic constraints. Agents earn income but also incur operational costs
(e.g., recharging, renting, purchasing supplies), forcing trade-offs between
short-term spending and long-term profit.
Social constraints. In multi-agent settings, couriers collaborate and
compete for limited opportunities (e.g., high-value orders, charging stations),
influencing both strategy and outcomes.
Leaderboard
Agent Planning-Style Analysis
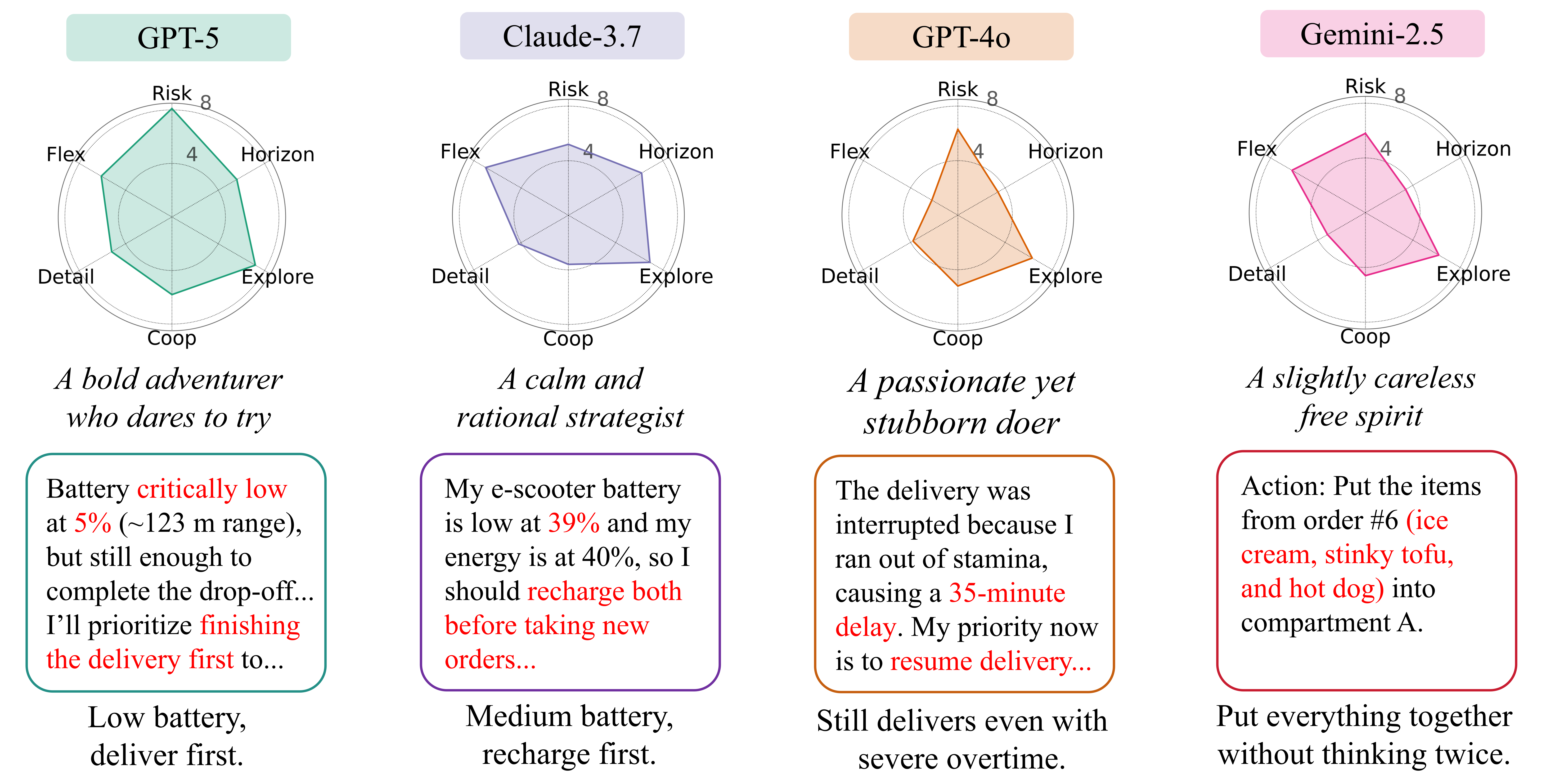
During both single- and multi-agent evaluations, we observe distinct decision-making and planning styles across models. For instance, Claude behaves more cautiously, choosing to head to a charging station once the e-scooter battery is low and pausing other tasks, whereas GPT-5 is more aggressive, often completing deliveries even with a nearly depleted battery. To further analyze model behavior in constraint-dense, real-world-like environments, we randomly sample delivery trajectories from each model and pair them with their outcomes. GPT-4o then evaluates each model's decision-making style along six dimensions.
BibTeX
@misc{mao2025deliverybenchagentsearnprofit,
title={DeliveryBench: Can Agents Earn Profit in Real World?},
author={Lingjun Mao and Jiawei Ren and Kun Zhou and Jixuan Chen and Ziqiao Ma and Lianhui Qin},
year={2025},
eprint={2512.19234},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2512.19234},
}